Benefits
- It is free for any use (private and commercial)
- Enterprise proven technologies
- Easy to use Graphical User Interface (GUI) for setup and administration
- Real High Availability (HA)
- Independent of hardware and hypervisor
- Accelerate your existing storage
- Use local storage of Hypervisors
- Zero-cost snapshots for asynchronous replication to another location
- It is not an one-way solution, you may migrate to any other solution that is based on ZFS
Features
OpenZFS is the most reliable and secure platform for storing and delivering. It is enterprise proven and it scales in performance and capacity (www.open-zfs.org).
The RawDR software stack makes this solution enterprise-ready and unique compared to all other free storage solutions based on ZFS. It delivers a GUI (graphical user interface) where you can setup and manage the appliances. You can configure HA, fix errors, shutdown appliances for maintenance tasks of the underlying hypervisor, etc.
Using NFS for virtual machines will lead to synchronous data transfer, each write command must be guaranteed to be saved by the NFS server. ZFS is a transactional filesystem and therefore groups writes to larger transactions groups. To keep this performance optimization this data is saved to the ZIL (ZFS Intent Log) which is kept either on all mirrors of a vdev or on a SLOG (Sepearated Log Device). Storing it on a vdev may dramatically reduce performance while storing the ZIL on a local SLOG would avoid the possibility to start the Zpool on another system. Our architecture allows the mirroring of all transactions to the memory of another node and so make it real high available without the need of any changes on client site. While this is much faster than the standard behavior you may also deactivate this sync at all (so called performance mode within RawDR) to get the maximum performance. This may lead to data loss (a few seconds, but data consistency would be maintained by ZFS) in the case of an outage and make it impossible for another node to automatically takeover this pool without crashing the VMs hosting it. If you let the VMs run on the same hypervisor as the Zpool delivers the NFS-share you will have have the maximum performance with minimum risk, because a hypervisor crash would crash all VMs running on it and so there would be no access to this nfs share any longer. Almost all modern filesystems can handle this (would be the same like an online snapshot). You may afterwards start the NFS-Share and the corresponding VMs of another hypervisor.
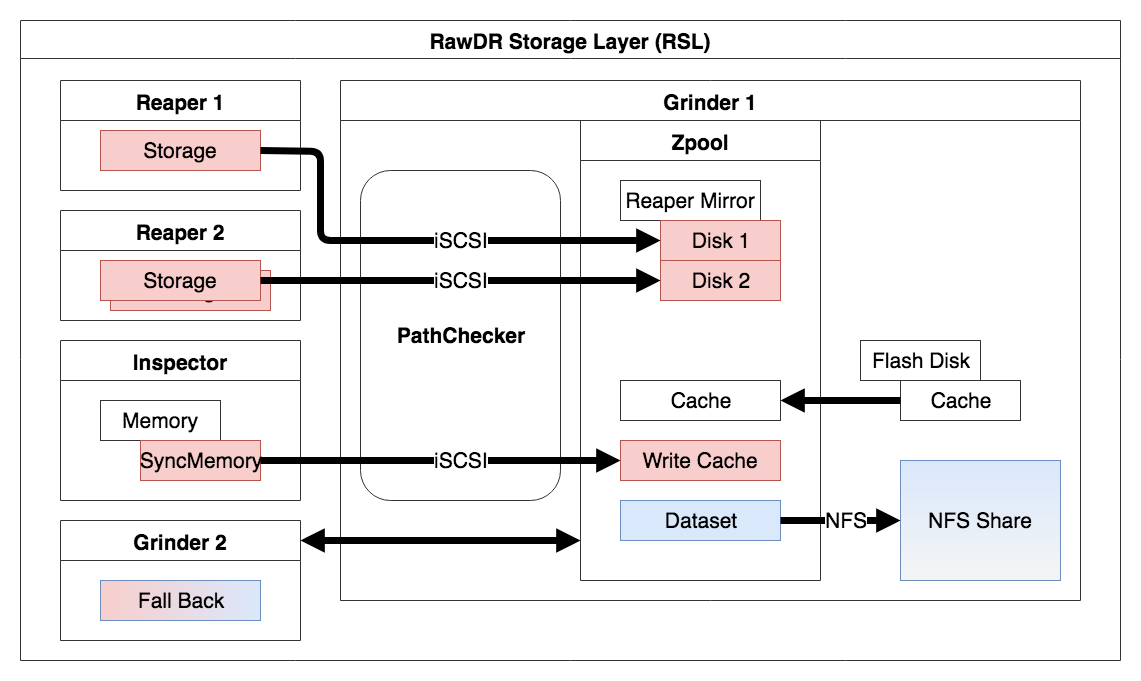
Next to this we also realized a PathChecker which permanently checks the quality of each path of each disk. If it detects an outage or even bad quality (when the disk slowly reaches the end of its life and on several enterprise storage is responsible for overall slow performance) it kicks out the path or even the entire disk. The error detection and failover takes a few seconds which is OK for almost all operating systems to stay alive and continue work. A nice Giveaway of the PathChecker is the realtime latency measuring of each disk, which can easily be processed by any monitoring tool.
Within RawDR you will mirror the data always to at least 2 independant storage backends. As these storage backends can be located in different datacenters you can get a synchronous data replication implicitly.
Within the Addons you also find a script which will handle the periodically creation of FULL and incremental snapshots to a network share. ZFS is a true transactional filesystem and therefore snapshots don't have any performance impact (in contrast to Copy-On-Write filesystems used by almost all hypervisors). On the roadmap is a feature called "warehouse" which will handle advanced snapshot management. It will periodically create incremental snapshots, restore them on any ZFS based solution and proceed cleanup tasks. While this continuously verifies the backup consistency, you will then have the capability to do a Point in Time Recovery from an offsite read-only data condition from where you can copy over an old vDisk to the Live system.
It can be deployed on any hypervisor. You can also mix hypervisors, e.g. VMWare and XenServer. KVM is coming soon.
As vDisks are represented as files via NFS, RawDR implicitly delivers Thin Provisioning. ZFS takes advantage of the realtime compression algorithm LZ4. While it saves space and offloads the storage backend, it is a prerequisite for space reclaiming by zeroing out at upper layer. As Writes are checksummed, it protects against silent data corruption (also known as Bit Rot). Silent data corruption becomes more and more important with the increasing size of disks and with the usage of Flash Disks. There are lot of long-terme studies from google and facebook which are talking about BER (Bit Error Rate) and silent data corruption. To summarize it up, the lack of checksumming is like "Russian Roulette" for your data.
Eliminates the need for All-Flash solutions and allows the usage of cheap NVMe modules for less than 0.4USD/Gigabyte while keeping data integrity. While these cheap NVMe must never be used as backend storage they are perfect for Read-Caching as we only need max Random Read IOPS and sequential writes. ZFS caching is aware of LRU (least recent used) and MFU (most frequently used), tiering in RAM and Flash-Memory and compresses it.
Through the ZFS technologies, random write workloads are collected to a transaction group which will be written sequentially to the storage backend. Thanks to the efficient read caching the read workloads will rarely hit the backend storage.
Most installations have a RAID1 with several 100GB of enterprise HDD space only for the Hypervisor while it only consumes less than 50GB. You may give this unused space to RawDR and get a high performance NFS storage solution at no hardware and software costs.
With RawDR you can even use local hardware RAID5 or TLC based SSDs like Samsung SM/PM863a. In general you must never use ZFS with hardware Raid, especially never with RAID5 or Raid6 because auto-repair could no longer take place. As RawDR will always mirror the backend devices (like RAID5) this restriction here is not valid. ZFS can still use its checksum detection and correction while you can enjoy the hardware replacement features of your server. By the way, the horrible slow random 4k write IO performance (80% of VDI IO) by RAID5/6 is compensated by the transactional filesystem layout of ZFS. There will only be sequential writes towards the storage backends where RAID5 has its strengths.
If local hardware RAID is too expensive you may consider the use of local SATA SSDs instead. The only requirement to use them as storage backend (in contrast to use them as cache) is power-loss protection. The following studies show that SSDs fail in a complete different way than HDDs. Please read them carefully and understand why you are playing russian roulette with your data if you use SSDs with a legacy RAID-solution instead of a checksum-based solution like ZFS. To summarize we represent the position: Better use TLC (e.g. PM863a) with ZFS instead of SLC with legacy RAID. Meanwhile you get datacenter TLC solutions with up to 4TB for less than 0.50$/GB. Protecting it with ZFS will protect you against SSD problems:
- A Large-Scale Study of Flash Memory Failures in the Field
- Reliability of nand-Based SSDs: What Field Studies Tell Us
Real HA-solution and possibility of online migrate NFS-shares between nodes, therefore neither Firmware Upgrades nor Node Replacements will force a Downtime of the NFS shares.
Roadmap
Planned new features
Auto-Actions
Changelog Version 2.3.6
Multi-User Support
Support for parallel GUI access towards the Storage Layer
Metrics
Show Live and historical Performance metrics graphical and support for email-alerting (currently available through command line)
Warehouse
Snapshot Management through GUI (currently available through command line)
CIFS Support
Support for CIFS-protocol at dataset level with full HA capability
Link-Checker
Extend LAGG by a Link-Checker (similar to the current PathChecker) to compensate the proprietary implementation of several NIC drivers
SR-IOV Support
Support for SR-IOV within the GUI (currently available through command line)
Hypervisor Extension
Extend Maintenance mode to support dependency groups (e.g. Hypervisor, Pool/Cluster or Datacenter)
Hypervisor Integration
Hypervisor integration with support of PCI-Passthrough and SR-IOV through GUI (currently available through command line)
Auto-Repair Support
Support for Auto-Repair (repair for failed nodes, spare nodes)
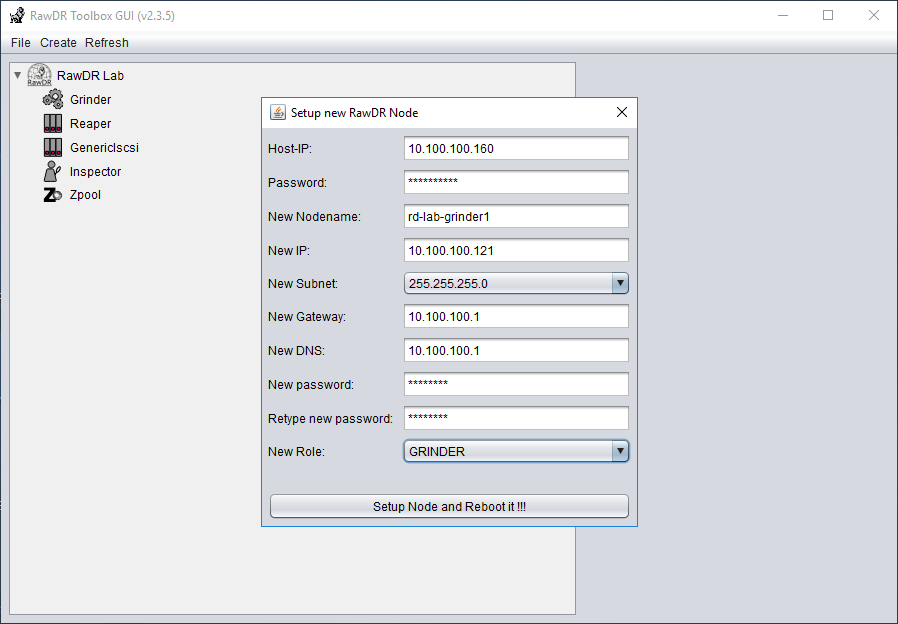
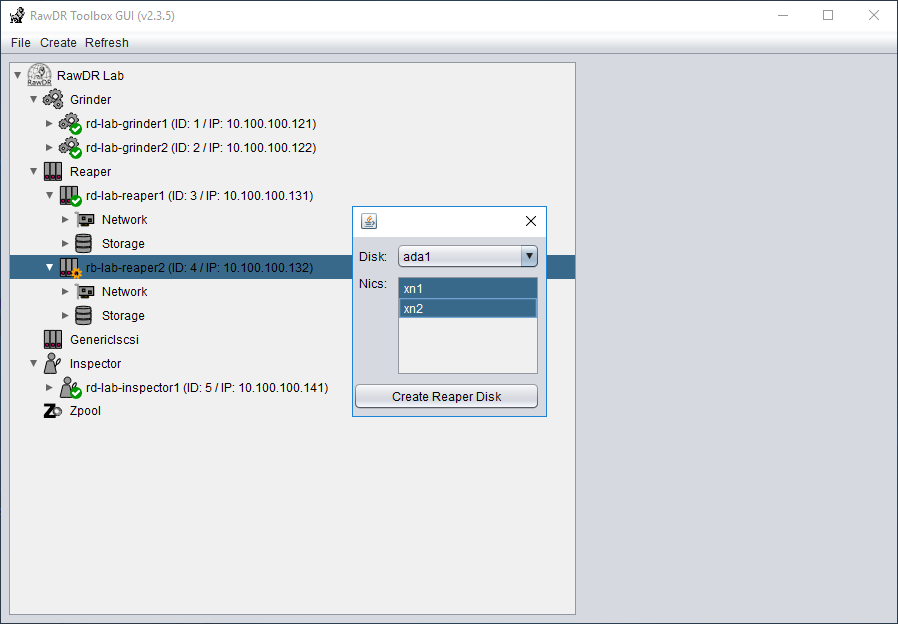
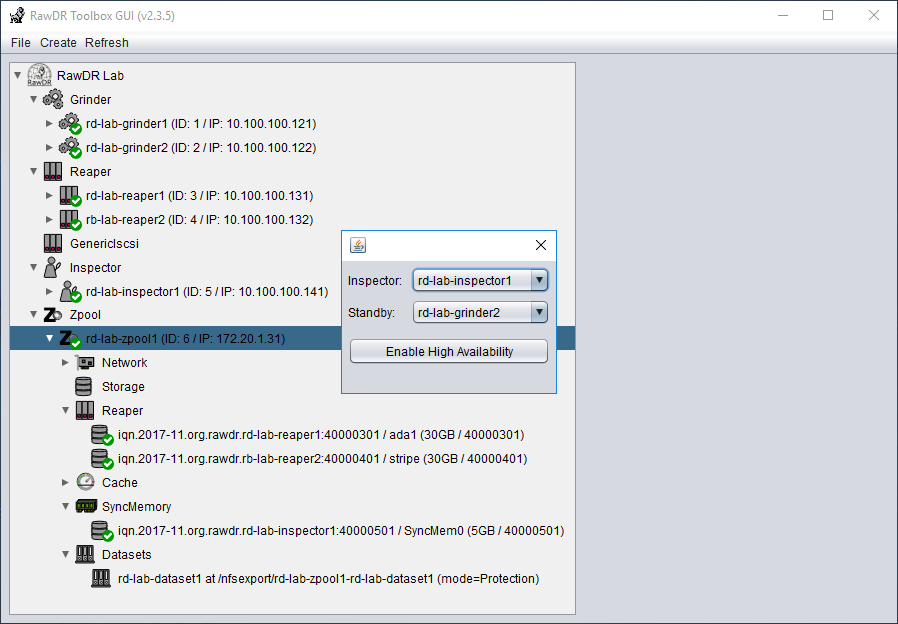
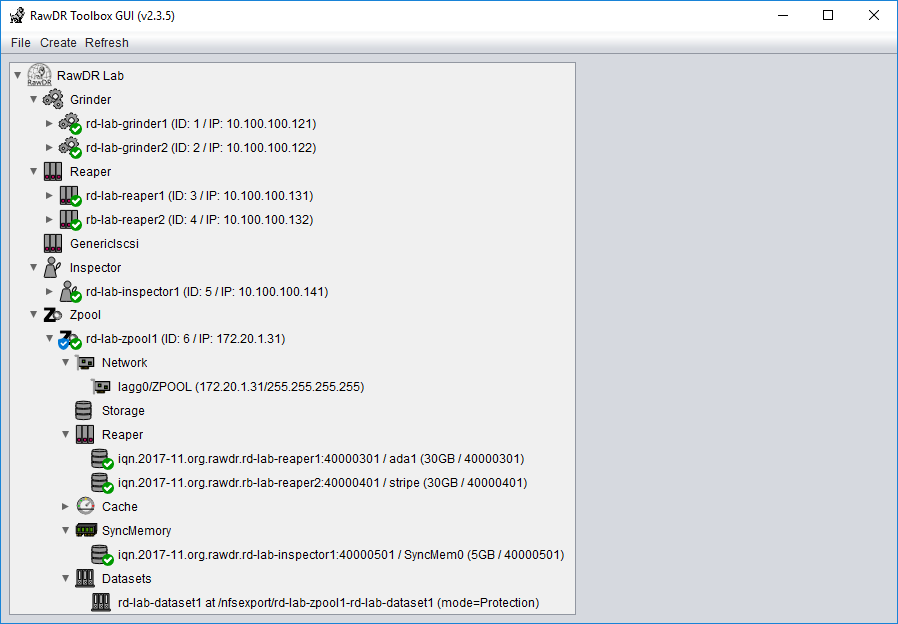
Screenshots
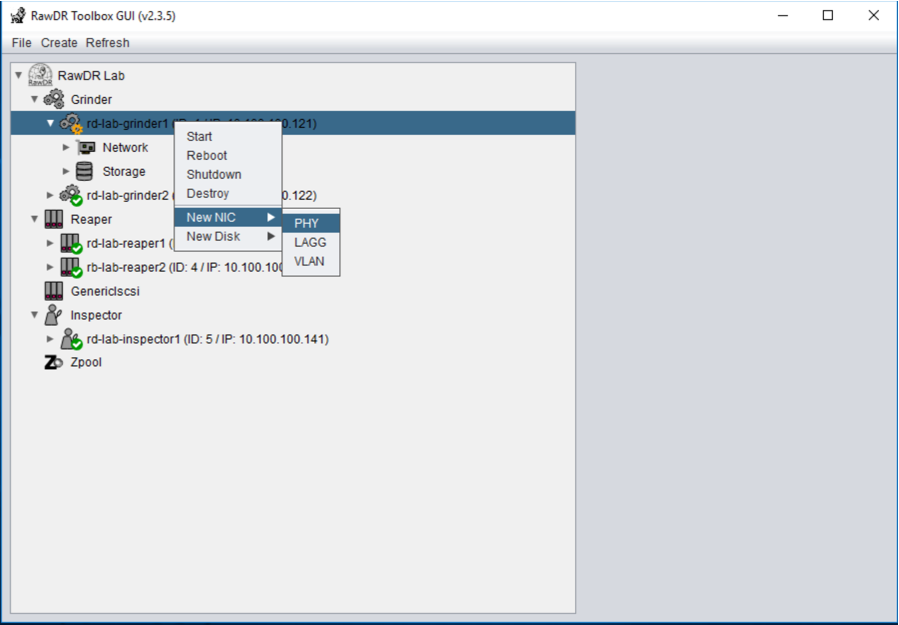
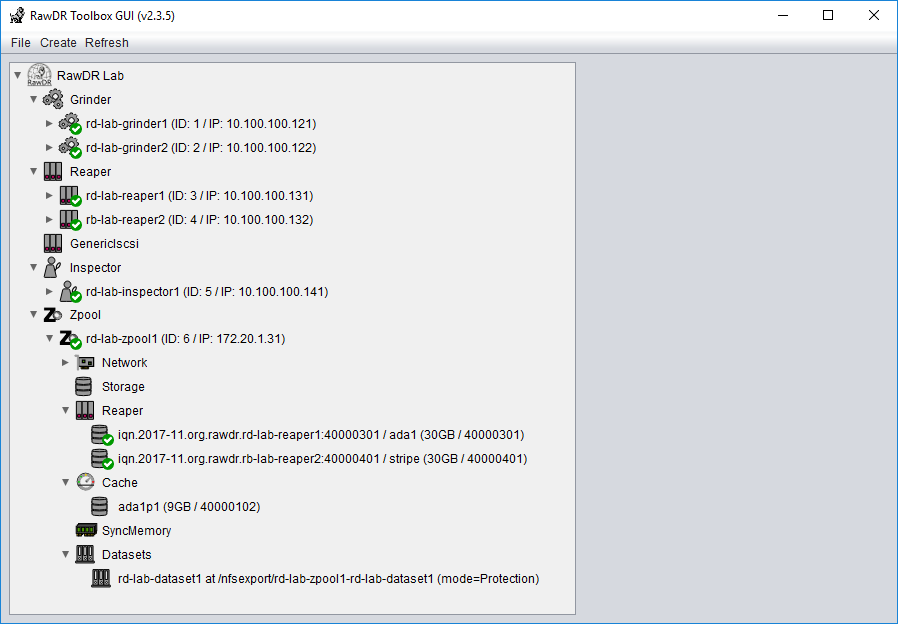
RawDR Setup
Grinder, Reaper, Inspector
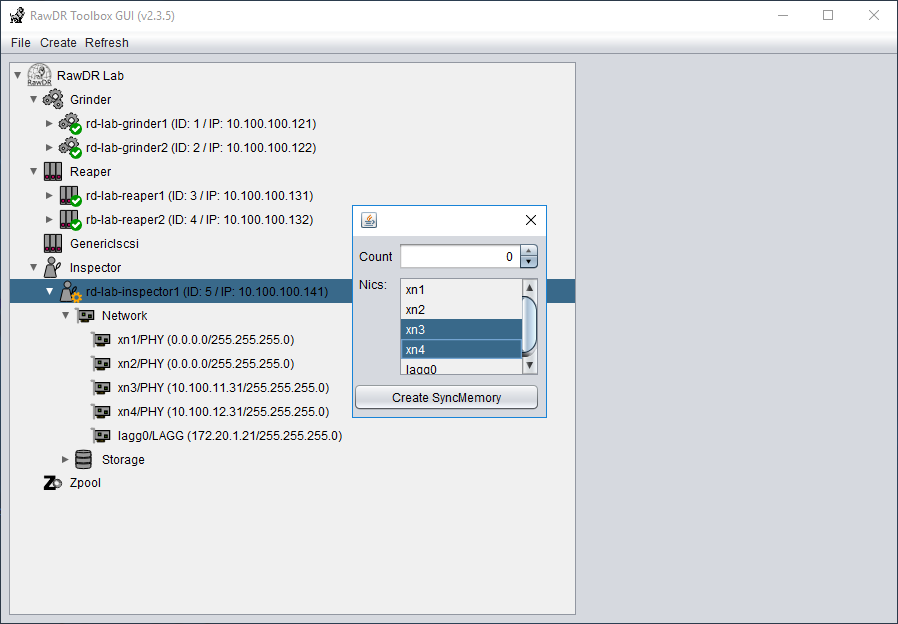
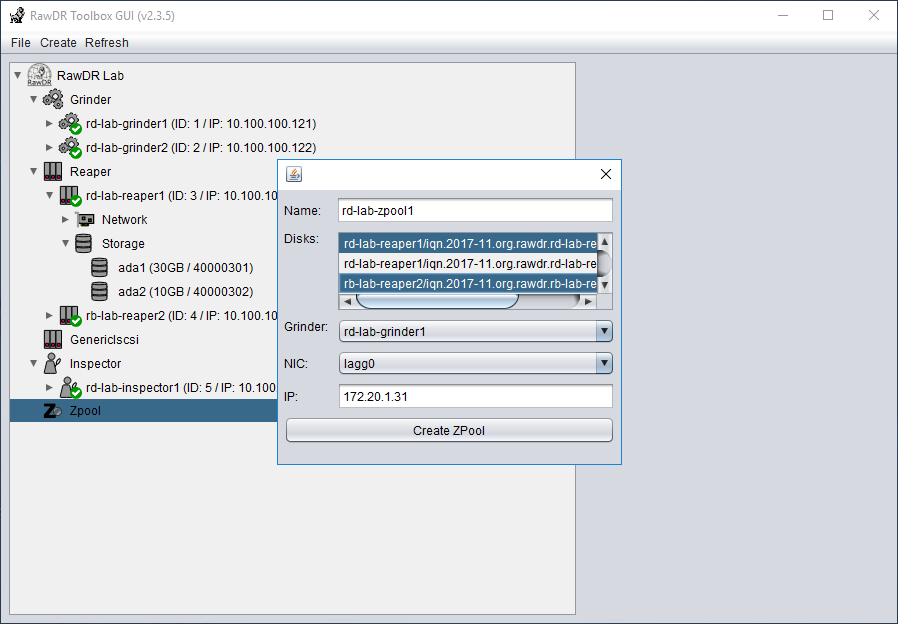
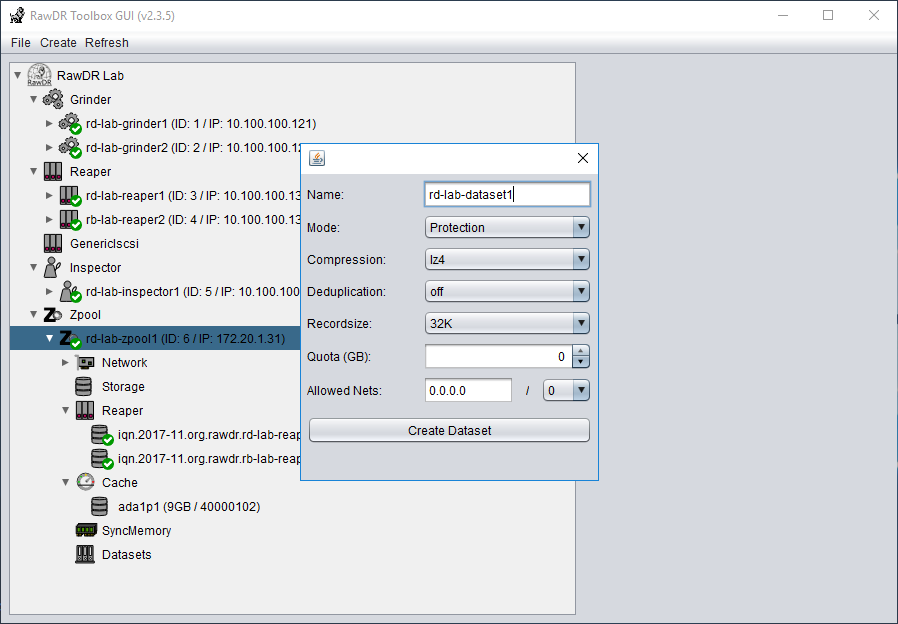
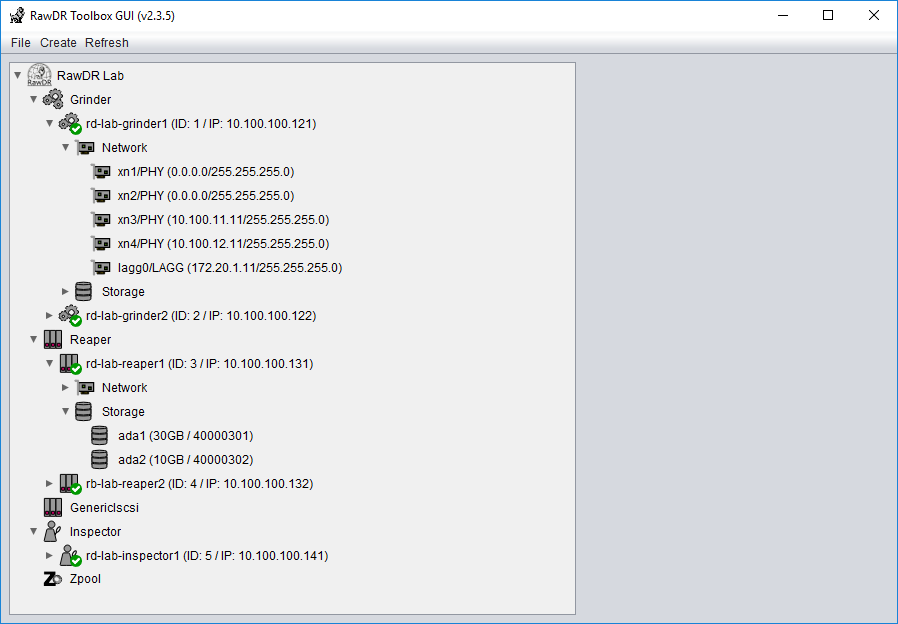
RawDR Management
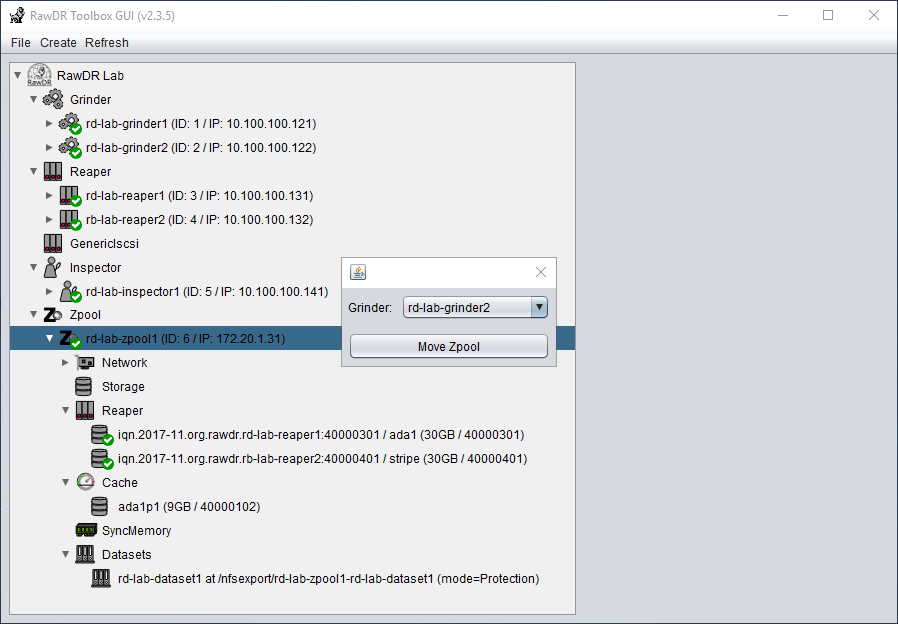
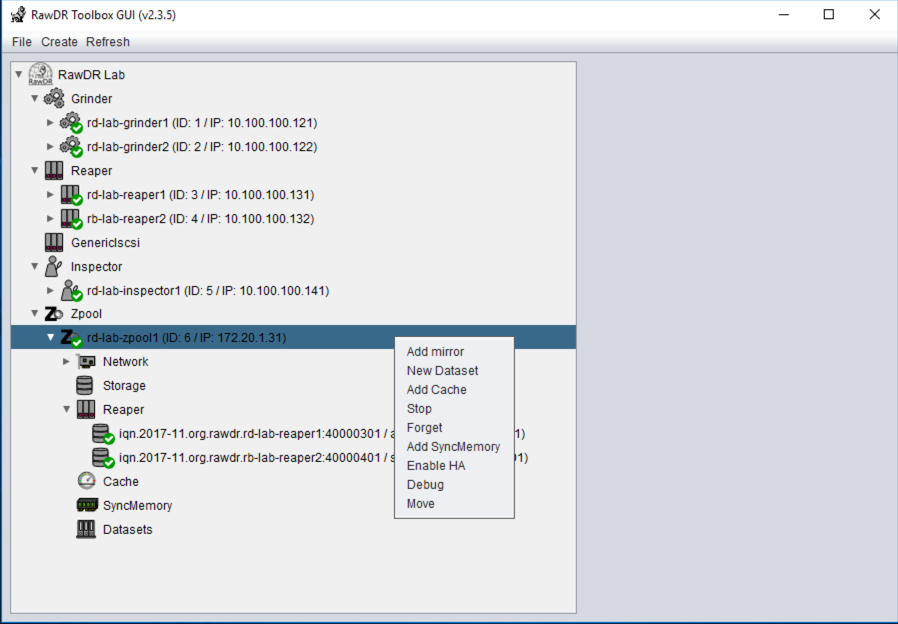
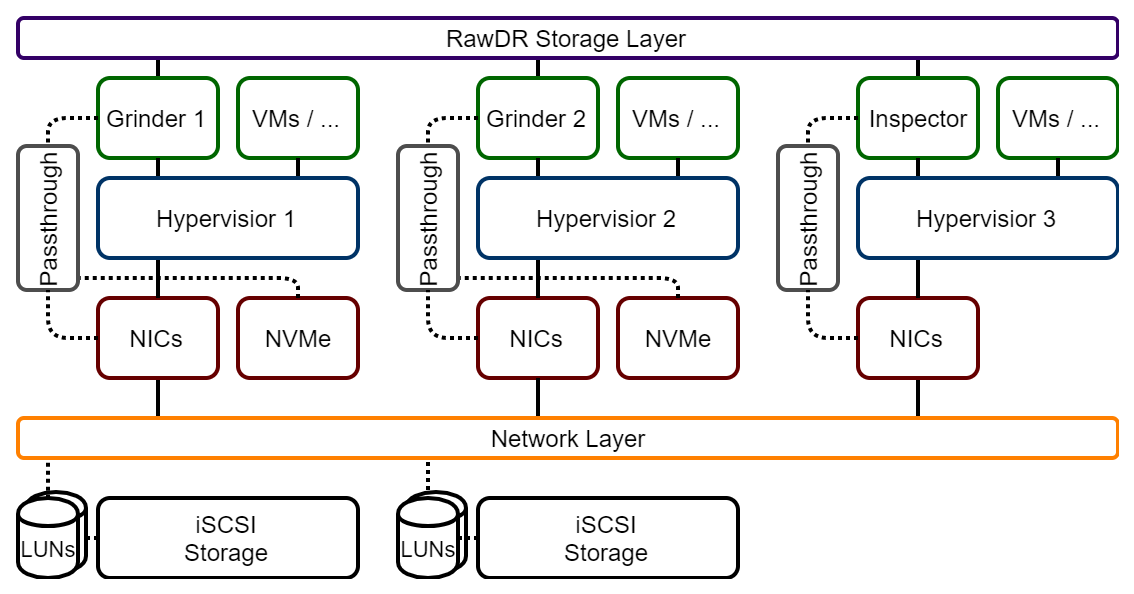
Architecture
RawDR Storage Layer
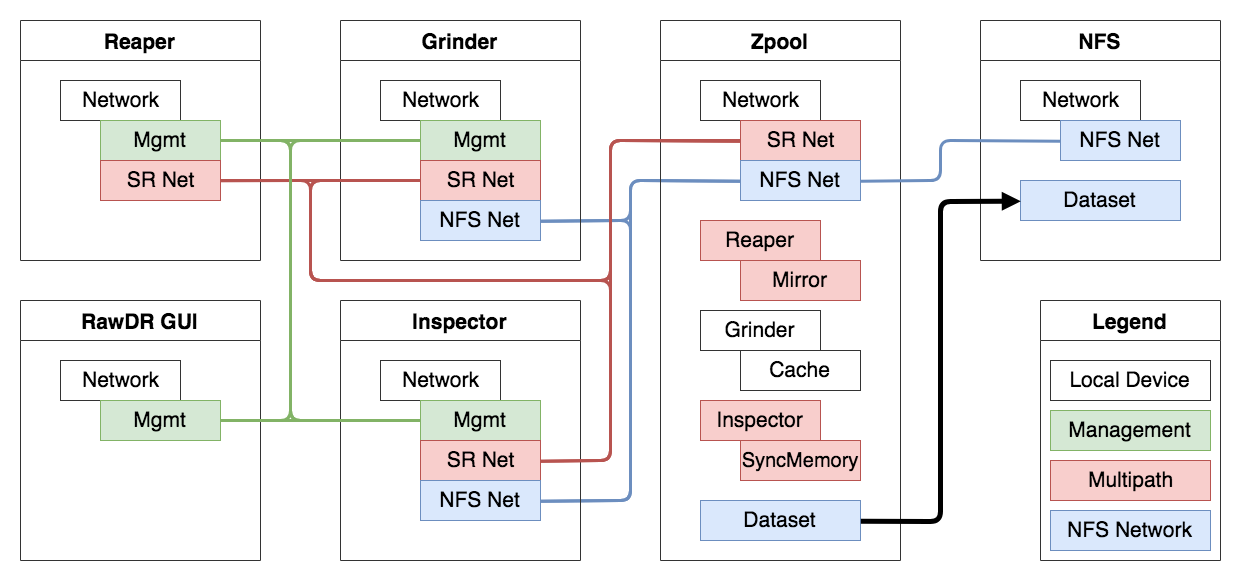
RawDR Network Layer
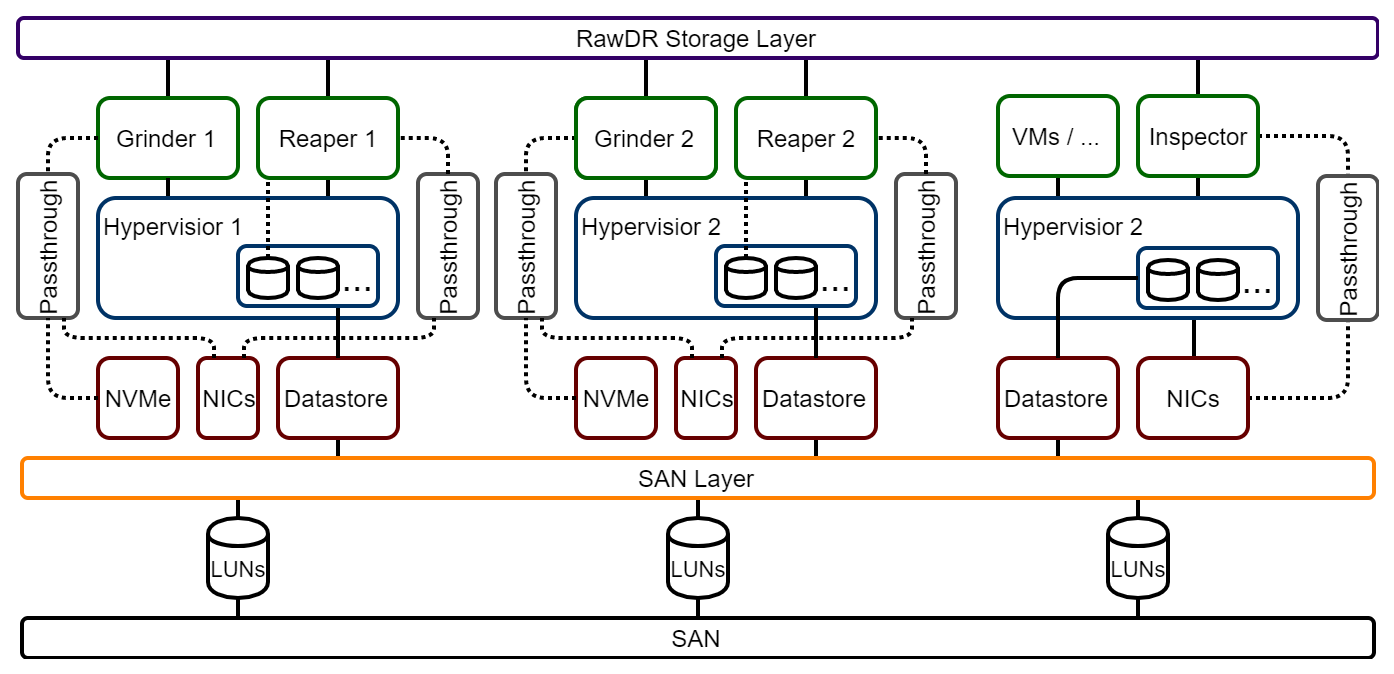
RawDR Hyperconverged Layered

RawDR Accelerator Layered
RawDR Hyperconverged Direct
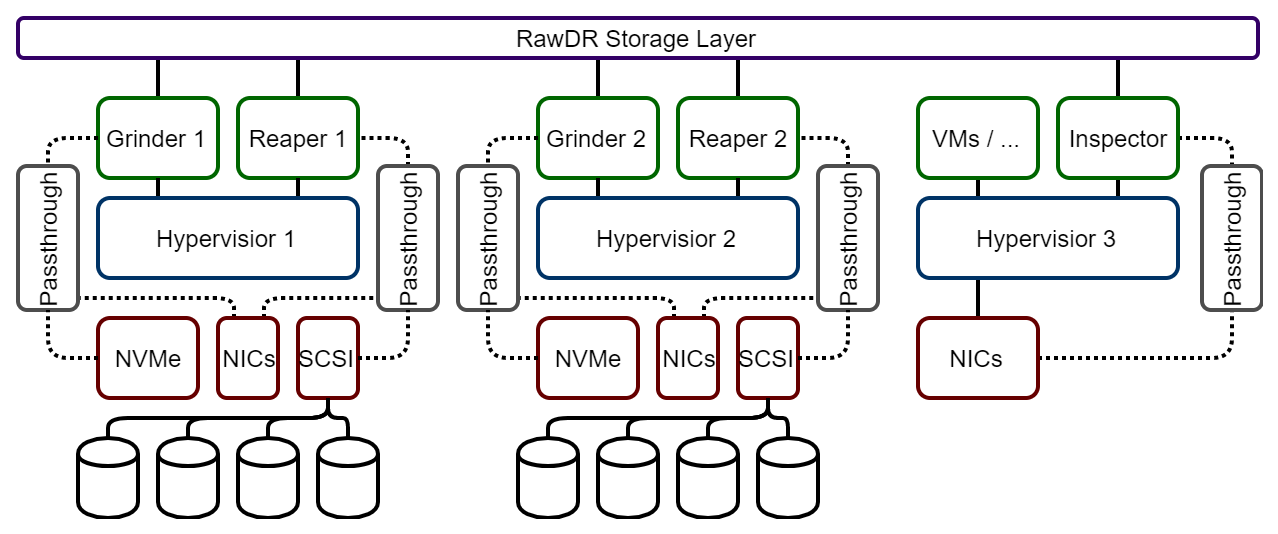
RawDR Accelerator Direct